Linux 进程调试
1. Linux进程的Core Dump机制
当Linux进程在运行过程中出现异常终止或崩溃,系统会将程序当时的状态记录下来,保存在一个core文件中,这种机制称为
Core Dump,又叫"核心转储"。core文件中包含了程序异常时的内存数据、寄存器以及运行堆栈等信息,开发人员可以使用调试工具来快速定位程序异常原因。
顺便说一句,在Linux中如果想看一个运行中进程的堆栈信息,可以查看
/proc/<pid>/stack文件的内容,如果一个进程hang住了,就可以大致确定范围。
Linux中对core文件的大小是具有一定限制的,ulimit -c是专门用来控制生成的core文件大小限制的。
1 | |
上面对Linux core文件大小限制的修改只是临时的,如果要将修改持久化需要写入配置文件里,这里有两种方式:
- 在
/etc/profile中添加ulimit -c unlimited,如果要让改变立即生效,可以source /etc/profile - 修改
/etc/security/limits.conf中:#* soft core 0取消注释后并改为* soft core unlimited
注意,ulimit的限制有
soft和hard之分,soft限制只是一种参考,超过该限制会警告,而hard限制则是强制的限制了。
注意:默认情况下,Linux的core文件限制为0,即不生成core文件。同时,当core文件限制太小时,生成的core文件可能被截断(可能导致无法正常调试)。一般core文件大小要比进程所占用的内存要大一些。
2. core文件的名称和生成路径
默认生成路径: 输入可执行文件运行命令的同一路径下
默认生成名字: 默认命名为core,新的core文件会覆盖旧的core文件
2.1 设置pid作为文件扩展名
1 | |
或者使用命令行指令
1 | |
2.2 修改core文件的保存位置
1 | |
上面这个指令将所有的core文件同一保存在一个路径中,并且包含额外信息,格式化字符的含义如下:
| 格式化字符 | 含义 |
|---|---|
| %p | pid |
| %u | uid |
| %g | gid |
| %s | the signal that caused the coredump into the filename |
| %t | the UNIX time that the coredump occurred into filename |
| %h | hostname |
| %e | the coredumping executable name |
2.3 永久修改
修改/etc/sysctl.conf配置文件,添加如下内容:
1 | |
随后执行命令立即生效:
1 | |
这时/proc/sys/kernel/core_pattern的值应该为之前设定的路径。
3. 对coredump生成的文件进行调试:
使用GDB调试一个程序,只需要二进制文件和相应的debug symbols(g++编译时可以通过-g参数将这些符号编译进二进制文件中)。而core文件包含相应程序崩溃时的堆栈信息。如果想要知道一个文件具体是不是core文件,可以:readelf -h <file>,-h参数是指定只显示file header部分,其中会包含文件类型的说明。
注意:如果二进制文件在编译时没有加上-g参数,那么后续调试时将只能看到调用信息,而无法通过
list指令看到每个函数的代码。
1 | |
当进入gdb交互终端时,可以用bt(backtrace的简写)来获取当前(程序崩溃时)的调用栈情况。在调用栈中,每个函数调用都包含一个对应的序号,可以用frame <number>来跳到指定的函数栈中。
当我们进入目标函数调用栈中后,就可以查看变量的值。使用info locals来看有哪些局部变量,使用print <variable>来打印某个变量的值。
gdb的指令非常多,如果不是一天到晚都在调试程序的话,指令还是很容易忘的,特别对于学生而言,很多时候学习gdb只是了解其可能的用途,很少在日常中频繁去使用,因此可以使用help指令来获取一些帮助信息。
4. 实际例子:
首先我们写一个会coredump的程序:
1 | |
为了能在调试时看到源码,加上-g参数:
1 | |
随后对其进行调试:gdb ./test ./core.1997745
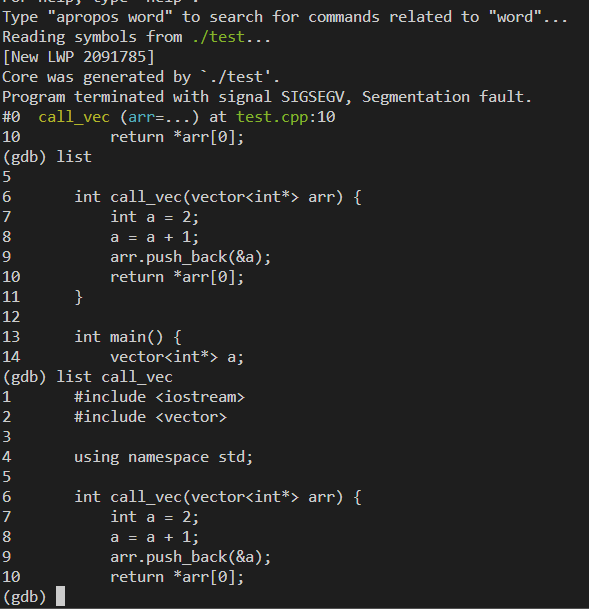
接下来可以切换调用栈中的函数,并打印局部变量或者参数等信息:
注:源码、变量等信息需要debug symbols才能看到,如果没有的话就只能看调用了哪些函数了。
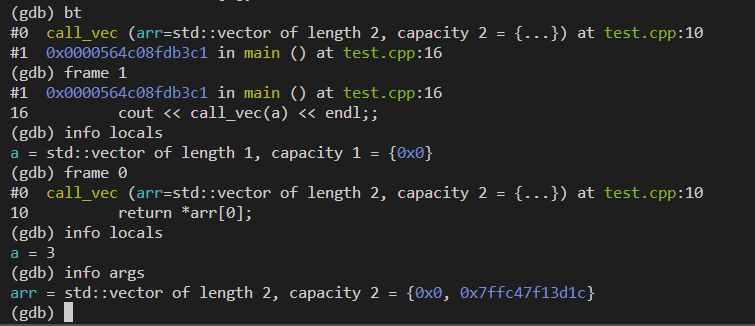
细心的话可以看到,当调用bt获取函数调用栈信息时,会给出是从函数哪一行进入下一层(或者崩溃)的。当使用frame <num>切换栈帧时,也会顺便打印一下是从哪一行进入下一层或崩溃的。
参考资料:
[1]: https://blog.csdn.net/anyegongjuezjd/article/details/107146541
[2]: https://stackoverflow.com/questions/5115613/core-dump-file-analysis